
Our SAE demo interface and API have been deprecated.
Understanding and Steering Llama 3 with Sparse Autoencoders
We're releasing a desktop interface for interpreting and controlling the behavior of Llama-3-8B using sparse autoencoders.
TL;DR
We're releasing preview.goodfire.ai, a desktop interface to help you understand and steer Llama 3's behavior. To do this, we trained interpreter models (sparse autoencoders) on Llama-3-8B to extract modifiable "features" from Llama 1Features are the internal concepts a model uses to generate output, often associated with specific neurons or groups of neurons that represent fundamental building blocks of the model's decision-making process..
In order to do this, we:
- Trained a state-of-the-art SAE on Llama-3-8B through extensive experimentation with various hyperparameters and dataset combinations, ultimately finding that the LMSYS-Chat-1M chat dataset produced the most effective features for chat applications
- Generated high-quality, human-readable labels for features using an automated interpretability pipeline
- Surfaced causal interventions by designing a gradient-based attribution method
- Generated meaningful model output changes with feature interventions while minimizing model performance degradation
What we did
It's commonly assumed that neural networks - particularly the large language models that power most of the advances in modern AI products - are black boxes, with internals we can neither understand nor control. Recent advances in interpretability research have demonstrated that this assumption is incorrect: we can in fact train interpreter models that parse neural network activations into components that are often human-understandable (these components are called "features"). The most successful class of interpreter models so far are known as sparse autoencoders (SAEs) [1]Interim Research Report: Taking Features Out of Superposition with Sparse Autoencoders [link]
Sharkey, L., 2022. Alignment Forum.[2]Sparse Autoencoders Find Highly Interpretable Features in Language Models [link]
Cunningham, H. and Sharkey, L., 2023. arXiv preprint arXiv:2309.08600.[3]Towards Monosemanticity: Decomposing Language Models With Dictionary Learning [link]
Bricken, T., 2023. Transformer Circuits., which we give a short introduction to below. We can also intervene on the "features" discovered by interpreter models in order to steer model behaviour in a precise, quantitative way.

Our first research preview is a familiar and easy-to-use chat interface that combines a large language model (Llama-3-8B-Instruct) with a sparse autoencoder model on the backend. The aim of this preview is to allow you to play with this setup and get a better understanding of what interpretability techniques can and cannot do. Most interpretability research so far has only been presented as papers, or limited to SAE feature browsers. We believe the only way to really understand the precise details of a technology is to use it: to see its strengths and weaknesses for yourself, and envision where it could go in the future.
Technical details
What are sparse autoencoders?

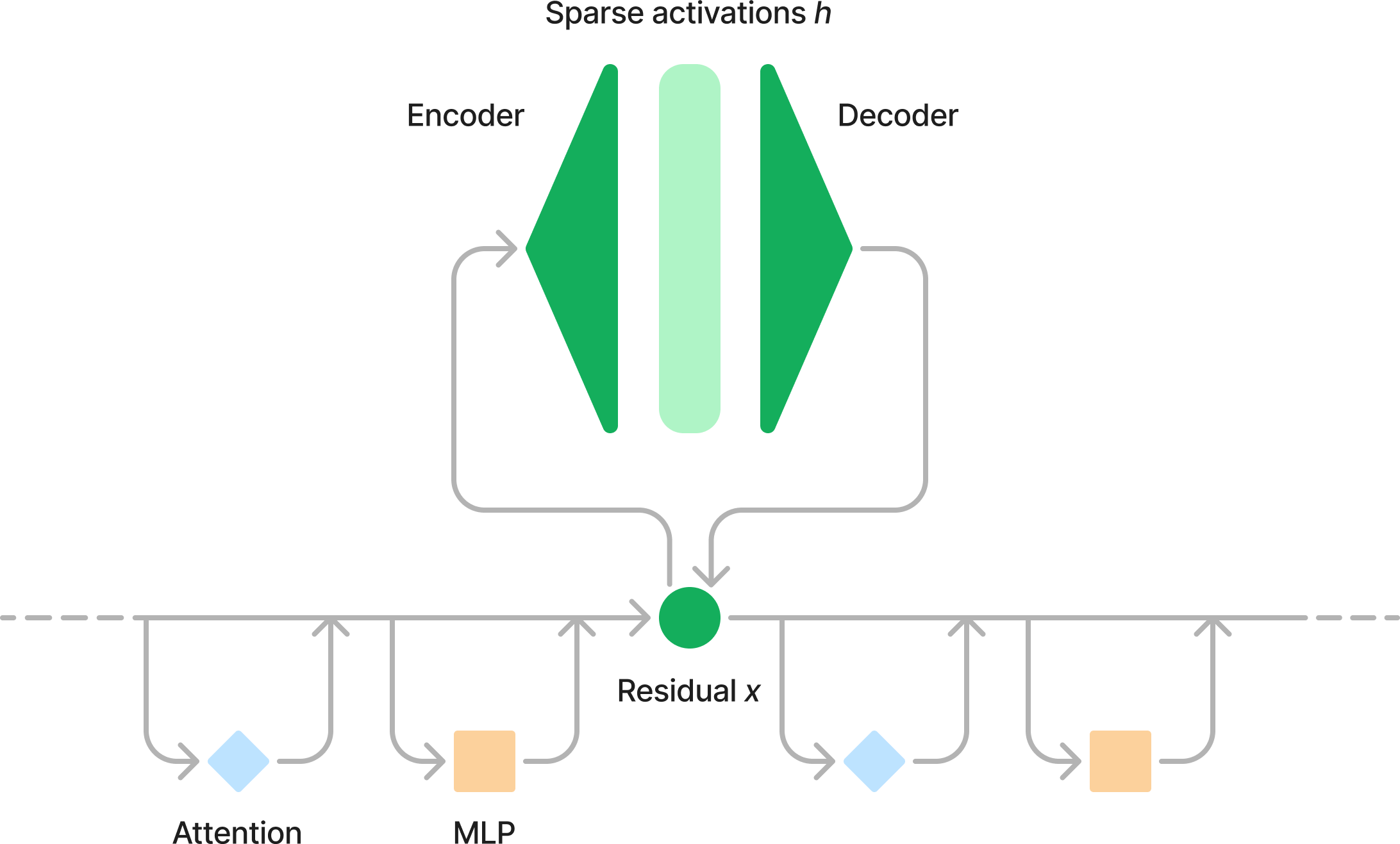
A sparse autoencoder is a type of autoencoder which is essentially a fancy two-layer multilayer perceptron (MLP) with a form of sparsity-promoting regularisation applied to the hidden layer.
Autoencoder models are neural networks that learn to compress input data into a lower-dimensional representation and then reconstruct it, effectively capturing the most important features. The compressed representation in the middle layer, often called the bottleneck or latent space, forces the model to learn efficient representations of the input data.
The intuition for why this model creates interpretable representations in the hidden layer is that neural network features 'want' to correspond to individual neurons, but by forcing them into a lower-dimensional representation, we cause them to get squashed together such that they no longer align with individual neurons. Although we think of neural network representations as very high-dimensional objects, in this picture they should be even higher-dimensional! This view is still largely an intuition with relatively limited empirical evidence outside of toy models [4]Toy Models of Superposition [HTML]
Elhage, N., 2022. Transformer Circuits., although the success of sparse autoencoders offers some support.
More formally, we extract LLM activations $x$ from some point in the model (in our case the residual stream at layer 19) and train a two-layer MLP to autoencode:
where $\sigma(\cdot)$ is some nonlinearity (we simply use ReLU, though other activation functions like top-k [5]Scaling and Evaluating Sparse Autoencoders [link]
Gao, L., 2024. arXiv preprint arXiv:2406.04093., Gated [6]Improving Dictionary Learning with Gated Sparse Autoencoders [link]
Rajamanoharan, S. and Nanda, N., 2024. arXiv preprint arXiv:2404.16014. and Jump-ReLU [7]Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders [link]
Rajamanoharan, S. and Nanda, N., 2024. arXiv preprint arXiv:2407.14435. have been tried as well). The hidden layer $h$ is typically substantially wider than the dimension of the residual stream $x$, which is a vector of size $d_{\text{model}}$. The width of $h$ is determined by the expansion factor $\alpha$: $d_{\text{hidden}} = \alpha d_{\text{model}}$.
Sparse autoencoders are typically trained using a reconstruction loss $L_{\text{recon}}$ and a sparsity-promoting loss $L_{\text{sparsity}}$. We use a mean squared error reconstruction loss and an L1 sparsity loss:
$$\begin{align*} L &= L_{\text{recon}} + \beta L_{\text{sparsity}} \\ L_{\text{recon}}(x,\hat{x}) &= \|x-\hat{x}\|_2^2 \\ L_{\text{sparsity}}(h) &= \|h\|_1 \end{align*}$$
We tune the value of $\beta$ but otherwise use the same settings as the Anthropic April update [8]Anthropic Circuits Updates — April 2024 [HTML]
2024. Transformer Circuits.. Our choices here were intentionally conservative: although more recent SAE architectures offer increases in performance along some proxy metrics, we were concerned that TopK and JumpReLU SAEs appear to have some very high-frequency features. Investigating these concerns in sufficient detail would have added considerable time to development of our first research preview, so we chose to prioritise simplicity & velocity. Deeply understanding the tradeoffs of SAE architectural alternatives in practical usage is an important topic for us in the future.
Sparse autoencoder training metrics
Our training losses are an L2 reconstruction error and an L1 sparsity-promoting loss, but we also use other metrics to evaluate SAEs. The simplest scalar metrics we track are the average L0 of the SAE and the fidelity.
Average L0 measures the mean number of nonzero features:
where $||\cdot||_0$ is the $L_0$ metric and $h(x_i)$ is the hidden vector produced on input activation $x_i$. We track this as an exponential moving average across batches in training. $L_0$ compares the relative sparsity of different SAEs but doesn't directly say anything about the interpretability of those features, although it's a common belief that SAEs with lower $L_0$ are more interpretable.
Our second important metric is fidelity, which measures the degree to which the SAE captures functionally-relevant components:
where $l_{\mathrm{SAE}}(x)$ is the log-loss of the network on input $x$ with the SAE inserted and $l_{\mathrm{ablated}}(x)$ is the log-loss of the network on $x$ with the SAE output set to zero.
Training data

We train our SAE on activations harvested from Llama-3-8B-Instruct. The SE training pipeline involves first running text input through the model, then extracting model activations (vector embeddings) for each token - you can see a diagram above. These activations are held in a buffer, then once this buffer is filled we shuffle the activations and write them to disk. Shuffled activations are loaded and used for training the SAE. This ensures that our data doesn't have unintended autocorrelation between training batches.
Because our use case is primarily chat-focused, the SAE we use in our research preview was trained on activations harvested from Llama-3-8B-Instruct on the LMSYS-Chat-1M dataset [9]LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset [link]
Zheng, L., 2024. ICLR.. This led to an interesting and diverse range of features relevant to our use case. Training on a non-chat model, or on non-chat datasets such as FineWeb [10]The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale [PDF]
Penedo, G., 2024. arXiv preprint arXiv:2406.17557., generated a range of interesting features but didn't transfer as well to chat applications. We conjecture that this is because many features that are causally relevant to model behaviour occur on chat-specific special tokens (such as features indicating that the model should respond in a certain style), and missing these by training on non-chat data prevents us from finding these behaviourally-relevant features.
We also experimented with more diverse data mixes, for instance including a range of instruct and chat data sources along with web text as we are limited by the availability of suitable chat data. Although these data mixes generated interesting and features with even higher diversity, the resulting SAEs had far more dead and very low-frequency features. We also found that although many of these features were interpretable, our qualitative impression was that they were much less suitable as intervention candidates than the features in the LMSYS SAE. Interestingly, this training protocol also lead to more dead and very low-frequency features than in the LMSYS-only SAE, perhaps because the number of training steps between examples of a given feature increases with greater data diversity.
To explain the lower performance of our datamix SAEs we conjecture that SAE features become interpretable before they become suitable for intervening upon (perhaps the encoder trains faster than the decoder, or more accuracy is required for a feature to become a good target for interventions). A natural consequence of this conjecture would be that as we increase the diversity of data, the diversity of features naturally increases, but if the dataset size is held constant then each feature will receive correspondingly less data and thus be comparatively undertrained. Because of this, we expect that more sophisticated data mixes are likely to perform better as we scale up SAE training further, and we expect to invest substantially in understanding the science of SAE training data.
Automated interpretability

SAE features are often interpretable, but don't come with any human-readable interpretation attached. In order to generate human-readable interpretations, we use an automated interpretability pipeline that draws on state-of-the-art methods. For each live feature in the SAE, we collect examples of inputs that activated that feature (these are typically the token on which the feature was activated and the preceding tokens). We collect examples from across the distribution of activation levels (i.e. not only the examples that maximally activated the feature) and ask Claude to determine what these activations have in common.
Although our automated interpretability pipeline works well in many cases, it can struggle with many of the most influential features as these often occur on special tokens, punctuation, or other 'pivot points' in model responses. As such, Claude typically (and unsurprisingly) identifies these features as being about the specific tokens, as opposed to the information that they store about their context. Developing an automated interpretability pipeline or agent that focuses on the causal effect of a feature (for example by ablating or increasing it) could improve this situation, as could better reasoning capabilities.
To score feature explanations generated by automated interpretability, we use the generated explanation to distinguish between a sample that activates the feature and a 'distractor' sample, on which the feature is not activated. The proportion of correctly identified samples gives a score for the feature, and aggregating these provides a score for the automated interpretability method. The contrastive approach (which Anthropic have also tried [11]Anthropic Circuits Updates — August 2024 [link]
2024. Transformer Circuits.) has the additional effect of weakly penalising polysemanticity, which makes it an interesting measure for comparing both SAEs and automated interpretability methods. This approach differs from the 'simulation' approach in the original automated interpretability paper [12]Language Models Can Explain Neurons in Language Models [HTML]
Bills, S., 2023. OpenAI., and is similar to recent work from Eleuther [13]Open Source Automated Interpretability for Sparse Autoencoder Features [link]
Juang, C., 2023. EleutherAI..
In addition we do a more stringent test: we test the ability of our automated interpretability labels to distinguish a feature from its label's 10 of its nearest neighbours in embedding space. For a given feature label, we find its ten of its nearest neighbours in embedding space, then provide a language model with the feature's description and four examples; one true example and three distractors. We repeat this process ten times to determine how reliably the model can distinguish between similar features - you can see the results below.

A further interesting direction for automated interpretability would be to build interpreter agents: AI scientists which given an SAE feature could create hypotheses about what the feature might do, come up with experiments that would distinguish between those hypotheses (for instance new inputs or feature ablations), and then repeat until the feature is well-understood. This kind of agent might be the first automated alignment researcher. Our early experiments in this direction have shown that we can substantially increase automated interpretability performance with an iterative refinement step, and we expect to be able to push this approach much further.
Interventions and attributions

Interventions
A key part of our research preview is the ability to surface causally-relevant aspects of the model's computation and intervene on them. These computational elements significantly impact the model's output, such that modifying them would lead to meaningful changes in result. To understand this process, we first need to explain how we introduce the SAE into model computations and perform interventions.
Remember that an SAE autoencodes a model's activations $x$ at some layer (layer 19, in our case). The SAE prediction $\hat{x}$ is imperfect, so there's an error term $\epsilon$. We want to intervene on SAE features, so let's make the dependence on $h$ explicit:
So now if we change $h \rightarrow \tilde{h}$ (for instance by changing the value of a feature) we change the output of the SAE to $\tilde{x} = f_{\mathrm{dec}}(\tilde{h}) + \epsilon$. The error term $\epsilon$ is unchanged, so everything the SAE hasn't captured is unaltered by our intervention on $h$. We now insert the modified activations $\tilde{x}$ back into the model and continue inference through all the remaining layers to the model output.
Attribution
We surface good intervention candidates by doing gradient-based attribution to SAE features, which is easy to do with backprop (this approach shows the effect of features at all token positions to a single output token). The loss we found most effective is the logit of the predicted token minus the mean of the logits:
where $\tau_t$ is the t-th token, $\tau_{\lt t}$ are the tokens up to position t, $\pi(\tau)$ is the logit of token $\tau$, and $\bar{\pi}$ is the mean of the logits. The intuition for using logits rather than the log-loss is that the gradient of $\log p(\tau_t)$ combines both the gradient for features that promoted the chosen token, and for features that suppressed predictions of other tokens, which was confusing to interpret. We also obtained interesting results using contrastive explanations (i.e. gradient for the difference between a pair of tokens) but the UX flow was more complex. The reason we use the logit mean $\bar{\pi}$ is to avoid surfacing features that increase the logit of many or all tokens.
Because the SAE is applied at every token position, computing $\nabla_h\mathcal{L}_{\mathrm{attrib}}$ leads to a gradient matrix of shape [seq_len, n_features]. Summing across token position reliably highlights effective and interpretable features for interventions, whereas other approaches like taking the maximum or showing token positions separately are much less reliable. We then show the top k features by summed attribution and allow you to intervene on them. We scale all interventions to be between the maximum value seen in our autointerp dataset $h_{\mathrm{max}}$ and $-h_{\mathrm{max}}$ (although SAE encoders can't output a negative value, this allows 'blocking' of a feature).
Intervention phenomenology
Playing with attribution and intervention rapidly and at scale has surfaced some interesting observations. Some features are easy to reliably intervene on, whereas other very similar-looking ones have little or no effect. We conjecture that this could be due to cross-layer distributed representations (AKA cross-layer superposition): if a feature is split across multiple layers spanning the point at which the SAE was trained, then the SAE will only see a portion of the feature vector, with the remainder of the vector being unchanged as they get computed in layers after the SAE has been used. This means that the majority of the feature isn't getting intervened upon.
As with other SAEs, we often find repeated 'echo' features, which seem to activate on similar inputs. This is relatively unsurprising under an L1 sparsity penalty, as two features of activation strength 1/2 will have the same L1 penalty as a single feature of strength 1 (though using $p$-norms with $p < 1$ would alleviate this). When we intervene on features with echoes we find that 'positive' interventions (i.e. turning on or strengthening a feature) normally work well with only a single feature intervention, whereas 'negative' interventions (trying to prevent a behaviour) frequently require more than one feature to be set to a negative value. This phenomenon could well be explained by self-repair, as a single positively-influenced feature may get amplified, whereas a single ablated feature could get restored. Deeply understanding the dynamics of feature interventions will be an important step towards more reliably steerable models.
Safety policy
At Goodfire, safety is at our core. We're a public benefit corporation dedicated to the mission of understanding AI models to enable safer, more reliable generative AI.
One application of our technology that we're excited about is advancing auditing and red-teaming techniques. We worked with the team at Haize Labs to highlight this capability, which you can read about here. We see a future together where steering models towards and away specific features can elicit jailbreaks and additional capabilities of models. We're committed to working with organizations like the amazing team at Haize Labs to advance safety research.
We also spent time prior to the release adding moderation to filter out a significant portion of harmful features, feature samples, and user inputs/outputs that violate our API categories. If you are a safety researcher that would like access to the features we've removed, you can reach out at contact@goodfire.ai for access.
In the future, we'll train interpreter models on larger and more capable foundation models. We are committed to making sure that our releases are safe, and will work with red-teaming and safety evals organizations to help ensure smooth and safe releases. We believe that understanding model internals is crucial for identifying shortcomings in generative models and guiding more effective safety research. We're excited to equip researchers with these tools and see what they can do over the coming months.
What's next?
We're actively developing a developer toolkit that incorporates the technology showcased in our preview, while simultaneously advancing the frontier of applied research. If you're interested in trying our product, sign up for our waitlist. And if you're passionate about shaping the future of interpretability, we'd love to hear from you!
Acknowledgments
We thank the team at Haize Labs for their collaboration on safety research and auditing applications of this technology.
Author Contributions
T.M. conceived and led the research. The Goodfire team contributed to the implementation and writing of the paper.
Footnotes
- Features are the internal concepts a model uses to generate output, often associated with specific neurons or groups of neurons that represent fundamental building blocks of the model's decision-making process.
Citation
T. McGrath et al., "Understanding and Steering Llama 3 with Sparse Autoencoders," Goodfire Research, Sep. 25, 2024. [Online]. Available: https://www.goodfire.ai/research/understanding-and-steering-llama-3
@article{mcgrath2024understanding,
author = {McGrath, Thomas and Balsam, Daniel and Deng, Myra and Ho, Eric},
title = {Understanding and Steering Llama 3 with Sparse Autoencoders},
journal = {Goodfire},
year = {2024},
month = {September}
}
References
- Interim Research Report: Taking Features Out of Superposition with Sparse Autoencoders [link]
Sharkey, L., 2022. Alignment Forum. - Sparse Autoencoders Find Highly Interpretable Features in Language Models [link]
Cunningham, H. and Sharkey, L., 2023. arXiv preprint arXiv:2309.08600. - Towards Monosemanticity: Decomposing Language Models With Dictionary Learning [link]
Bricken, T., 2023. Transformer Circuits. - Toy Models of Superposition [HTML]
Elhage, N., 2022. Transformer Circuits. - Scaling and Evaluating Sparse Autoencoders [link]
Gao, L., 2024. arXiv preprint arXiv:2406.04093. - Improving Dictionary Learning with Gated Sparse Autoencoders [link]
Rajamanoharan, S. and Nanda, N., 2024. arXiv preprint arXiv:2404.16014. - Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders [link]
Rajamanoharan, S. and Nanda, N., 2024. arXiv preprint arXiv:2407.14435. - Anthropic Circuits Updates — April 2024 [HTML]
2024. Transformer Circuits. - LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset [link]
Zheng, L., 2024. ICLR. - The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale [PDF]
Penedo, G., 2024. arXiv preprint arXiv:2406.17557. - Anthropic Circuits Updates — August 2024 [link]
2024. Transformer Circuits. - Language Models Can Explain Neurons in Language Models [HTML]
Bills, S., 2023. OpenAI. - Open Source Automated Interpretability for Sparse Autoencoder Features [link]
Juang, C., 2023. EleutherAI.